
Als der legendäre Produzent Rick Rubin, der bereits mit Red Hot Chili Peppers, System of a Down1 und Johnny Cash zusammengearbeitet hat, vor wenigen Monaten zum unfreiwilligen Maskottchen des Vibe Codings2 wurde, erkannte er schnell die Ironie der Situation: “Ich bin der Plattenproduzent, der nichts über Musik weiß – also macht es Sinn, dass es einen Coder geben könnte, der nichts über Coding weiß”. Was als Internet-Meme begann, wurde zur Metapher für eine entstehende Praxis im Umgang mit Technologie – eine, die heftig umstritten ist und die Community spaltet.3 Claude 4 ist einer der vielen Beschleuniger dieses Symptoms und ein weiteres Beispiel dafür, dass sich LLM weiterhin hochskalieren und für Bereiche wie die Codeerzeugung kontinuierlich verbessern lassen.
Rubin erschuf dann aber ernst gemeint The Way of Code4, ein Kunstprojekt über die zeitlose Kunst des Vibe Codings, inspiriert vom rund 2.500 Jahre alten Dao De Jing.5 Rubin verkörpert eine Arbeitsweise, die auf Intuition und künstlerischem Gespür basiert – genau das, was Vibe Coding angeblich von traditioneller Programmierung unterscheidet.
Die Debatte um Vibe Coding hat jedoch auch scharfe Kritiker:innen: Der Blogger tante warnt eindringlich vor den Gefahren unreflektierter KI-Nutzung und bezeichnet die versprochene Demokratisierung des Programmierens als Lüge.6 Seine Kritik trifft wichtige Punkte, verkennt aber die Möglichkeiten differenzierter Ansätze und die Notwendigkeit zu akzeptieren, dass Menschen kreativ und sinnvoll mit KI-Unterstützung programmieren und arbeiten können.
Als Entwickler im Bereich der Digital Humanities ist es mein Selbstverständnis, Tools für Forscher:innen zu entwickeln. Meine gesamte Dissertation7 handelt von diesem Thema und mündete in meinen Überlegungen zu Promptotyping. Promptotyping8 beschreibt ein dreistufiges Framework zur methodisch strukturierten, LLM-gestützten Konzeption und Entwicklung digitaler Werkzeuge für die Forschungspraxis. Es integriert Prompt Engineering, iteratives Requirements Engineering und kritisch-epistemische Reflexion, um Frontier-LLM als aktive Entwicklungspartner zu nutzen. Dies ist jedoch noch keine finale Definition, sondern meine aktuelle Auffassung, die ich laufend mit diesen Blogbeiträgen weiter ausarbeiten möchte. Es ist keine Demokratisierung des Programmierens – man muss wissen, wie Programmierung und Software Entwicklung funktioniert und, noch wichtiger, was man wirklich als Workflow, Modell oder Tool haben möchte. Aber ein LLM wie Claude 4 kann genau dabei helfen.
Weder der Human-in-the-Loop noch der Expert-in-the-Loop-Ansatz sind ausreichend. Erforderlich ist vielmehr eine kritisch-epistemische Reflexion in Form eines (noch näher zu definierenden) Critical-Expert-in-the-Loop. Diese Reflexionsebene muss sich sowohl in der allgemeinen Interaktion als auch spezifisch in der Prompting-Praxis niederschlagen. Ein zentrales Problem ist das als Sycophancy oder Yes-Man-Problem9 bekannte Verhalten von LLMs, also ihre Tendenz zur unkritischen Zustimmung. Da Transformer-Modelle ihre eigenen Ausgaben nicht verstehen, aber durchaus zur nachträglichen Verifikation fähig sind10, erfordert der Critical-Expert-in-the-Loop eine doppelte Reflexionsschleife: die menschliche Prüfung und die maschinelle Selbstkritik. Zweiteres bezeichne ich im Prompting als Critical Questioning oder Poking.
Mein Experiment mit Claude Sonnet 4 demonstriert diesen Ansatz: In zwei Stunden entstand ein funktionsfähiges Timeline-Annotationstool11 für das Stefan Zweig Digital Projekt. Es wurde vollständig “vibe-coded”, aber mit entscheidendem Unterschied. Als Critical-Expert-and-Developer-in-the-Loop, der sowohl kritisch-epistemische als auch kritisch-technische Reflexion vereint, praktizierte ich eine Art strukturiertes Vibe Coding als experimentelle Form des Promptotyping. Ich wusste genau, welche Fragen zu stellen und wann einzugreifen war, ließ aber bewusst Raum für die intuitive, fließende Dynamik des Vibe Coding.
Wenn strukturierte Forschungsdaten und ein konkretes Ziel wie ein Annotationstool vorliegen, verfügt das LLM bereits über ausreichend Kontext für zielgerichtete Lösungen. Das Ergebnis ist ein datengetriebener, extrem schnell erzeugter Prototyp, der direkt in einem Forschungsprojekt eingesetzt werden könnte oder zumindest Möglichkeitsräume für die Entwicklung von Forschungswerkzeugen eröffnet.
Anthropic & Claude 4
Am 22. Mai 2025 veröffentlichte Anthropic Claude 4 in zwei Varianten: Claude 4 Opus als leistungsstärkstes Modell und Claude 4 Sonnet als mittleres Modell, das auch kostenlos12 verfügbar ist.13 Anthropic bewirbt insbesondere die Reduzierung von over-eagerness, das Phänomen, dass frühere Claude-Versionen auf einfache Programmieranfragen mit umfangreichen, nicht angefragten Code-Überarbeitungen reagierten.14 Für das hier dokumentierte Experiment wurde Claude 4 Sonnet verwendet. Opus ist zwar das größere Modell mit mehr Parametern und umfangreicherem “Weltwissen”, eignet sich aber nicht automatisch für alle Aufgaben besser als Sonnet.
In der aktuellen KI-Landschaft positioniert sich Anthropic als Unternehmen, das sich nicht nur auf Coding und Software-Entwicklung durch LLMs fokussiert und dabei eine führende Rolle hat, sondern auch auf die Entwicklung sicherer KI-Systeme. Alignment15 – die Sicherstellung, dass KI-Systeme kontrollierbar und sicher agieren – ist keine nachgelagerte Überlegung, sondern eine Kernkomponente ihrer Entwicklungsstrategie. Ihr Race to the Top16 versucht, KI-Sicherheit als Wettbewerbsvorteil zu etablieren, während die Responsible Scaling Policy17 mit dem ASL-Framework konkrete Sicherheitsstufen definiert. Claude Opus 4 wurde vorsorglich unter ASL-318 freigegeben. Dabei handelt es sich um eine Sicherheitsstufe, die verstärkte Schutzmaßnahmen gegen Missbrauch für CBRN-Waffen19 und besseren Schutz der Modellgewichte erfordert, da diese Modelle potenziell Fähigkeiten besitzen, die bei gezieltem Missbrauch in gefährlichen Bereichen eingesetzt werden könnten. Die Notwendigkeit der ASL-3 Sicherheitsstufe, also hochoffiziell potenziell gefährliche Modelle, wird bei Anthropic aber noch evaluiert.
Anthropic veröffentlicht nicht nur ihre Prinzipien zu einer Constitutional AI20, die explizite Werteprinzipien anstelle impliziten Feedbacks verwenden, sondern macht auch beispielsweise System Prompts21 und umfangreiche Forschung22 öffentlich zugänglich. Diese Offenheit steht im deutlichen Kontrast zu anderen Techfirmen. Der CEO Dario Amodei warnt eindringlich, dass die Modelle innerhalb der nächsten Jahre noch deutlich besser werden.23 Ob diese Selbstdarstellung der Realität entspricht oder Marketing ist, oder wie ich glaube, einfach beides, muss jede und jeder für sich selbst entscheiden. Es könnten doch einfach verantwortungsvollere Techno-Kapitalisten geben, die zwar ordentlich Kohle machen und in die Geschichte eingehen wollen, aber gleichzeitig sehen, dass die Technologie wirklich Gefahren mit sich bringt. Vielleicht sind Anthropic die “Not so Evil Guys”, die wir eher unterstützen sollen. Das ist aber nur meine persönliche Einschätzung.24
Edit: “Not so Evil Guys” ist bewusst gewählt, weil es auch bedeutet, dass sie als Techkonzern Daten stehlen: “Anthropic is a late-blooming artificial intelligence (“AI”) company that bills itself as the white knight of the AI industry. It is anything but.”
Promptotype: Timeline-Annotations-Tool für Stefan Zweig Digital
Die digitale Nachlassrekonstruktion Stefan Zweig Digital25 des Literaturarchivs Salzburg, an der ich seit 2017 als Entwickler arbeite, stellt über einen Disseminator im GAMS26 digitalisierten Korrespondenzen bereit. Die Daten liegen als XML-Struktur vor und enthalten Metadaten zu Titel, Datum, Ersteller:innen und Mitwirkenden. Da ich alle Parameter gut kannte, bot sich hier eine ideale Gelegenheit für ein Experiment, einen sogenannten Vibe-Check27, um ein Gespür dafür zu bekommen, wie Claude Sonnet 4 tickt und was es leisten kann. Hier ist der Link zum Prototyp des Timeline-Annotations-Tool: https://dhcraft.org/excellence/promptotyping/szd-annotation-timeline/
Der Prompt war sehr konkret formuliert und damit kein eigentliches Vibe Coding mehr. Gefordert wurde eine Timeline aller Briefe, die direkt auf Basis der XML-Daten mittels JavaScript als Single Page Application umgesetzt werden sollte. Zur Verdeutlichung wurde ein Ausschnitt aus der XML-Struktur bereitgestellt, sodass Claude die genaue Datenstruktur kennenlernte. Die Informationen über die Daten und deren Struktur oder Modell werden typischerweise beim Promptotyping in einem sogenannten Promptotyping Document, wie DATA.md, abgelegt. Ausführlichere und konkrete Anforderungen an die Anwendung oder das Tool gehören in das Dokument REQUIREMENTS.md. Alle weiteren Informationen, etwa methodische Überlegungen, Kontext, Reflexionen oder sonstige Erläuterungen, werden im Dokument README.md festgehalten. Da dieses Beispiel nicht so umfangreich war, reicht es, alles in einem Prompt zu beschreiben.
XML snippet: gams.uni-graz.at/…/getMetadata
<sparql xmlns="http://www.w3.org/2001/sw/DataAccess/rf1/result">
<head>
<variable name="container"/>
<variable name="cid"/>
<variable name="pid"/>
<variable name="model"/>
<variable name="title"/>
<variable name="identifier"/>
<variable name="creator"/>
<variable name="contributor"/>
<variable name="date"/>
</head>
<results>
<result>
<container>Korrespondenzen</container>
<cid>context:szd.facsimiles.korrespondenzen</cid>
<pid uri="info:fedora/o:szd.161"/>
<model uri="info:fedora/cm:dfgMETS"/>
<title>Theaterkarte zur Uraufführung von „Jeremias" 1918, SZ-SDP/L2</title>
<identifier>o:szd.161</identifier>
<creator>Zweig, Stefan</creator>
<contributor bound="false"/>
<date bound="false"/>
</result>
<!-- ... -->
<result>
Das zeigt die Korrespondenzstücke mit:
<title><date>(optional)<creator>(optional)<contributor>(optional)
Ich möchte eine timeline aller dieser Briefe erzeugen. Und zwar möchte ich das XML direkt fetchen mit JavaScript und eine Single page Application erzeugen, bei der ich runterscrollen kann, damit ich die Sequenz der Briefe habe.
Können wir das umsetzen? Denke Schritt für Schritt.
Eine der zentralen Voraussetzungen für den Erfolg des Experiments war ein vorhandenes technisches Grundverständnis. Begriffe wie “fetchen”, “JavaScript” oder “Single Page Application”, also Grundwissen im Bereich der Webentwicklung, sind sehr wichtig, um ein Modell in die richtige Richtung zu lenken. Mit “Single Page Application” haben wir beispielsweise ein spezifisches Feature im LLM aktiviert, das sich von anderen Implementierungsansätzen unterscheidet. Während “Single Page Application” typischerweise eine einzelne HTML-Datei mit eingebettetem JavaScript und CSS triggert, würde der Begriff “Web App” eher zu einer React-basierten Implementierung führen. Solche begrifflichen Nuancen bestimmen maßgeblich die Architektur der generierten Lösung. Genau das ist Prompt Engineering.
Solche scheinbar marginalen Details führen in der praktischen Umsetzung schnell zu komplexen Fehlern. Anders gesagt: Alle blöden Fehler, die man als Entwickler:in auch macht, bleiben ärgerlich – egal ob Mensch oder Maschine. Aus Erfahrung kennt man die Klassiker und kann vorbeugen: Verwirrungen bei Variablennamen, Dateipfaden oder unklaren Namespaces. Entscheidend ist auch die Synchronisation: LLM und Entwickler:in müssen immer denselben Stand haben, manuelle Änderungen müssen zurück ins LLM kommuniziert werden. Noch ist das lästiges Herumkopieren mit viel Mikromanagement – aber wer, wie ich, viel WarCraft, StarCraft oder Age of Empires gespielt hat, sollte das doch schaffen! ;)
Ein Screenshot der originalen Stefan Zweig Digital Website diente als Design-Referenz. Die Anweisung Orientiere das Design am Screenshot übertrug ästhetische Anforderungen.
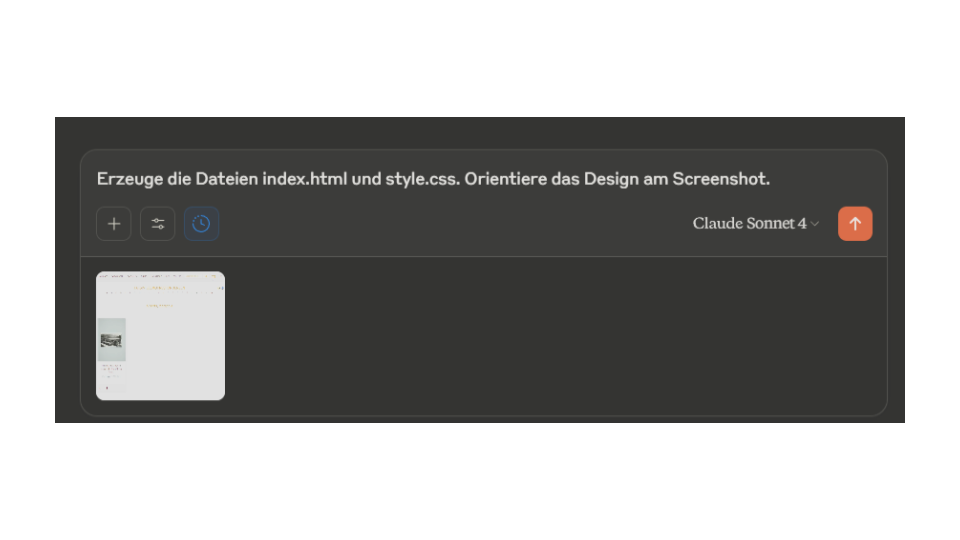
Es ist auch wichtig, dass man nicht alles auf einmal implementiert, sondern es schrittweise umsetzt, so wie man es auch selbst entwickeln würde: Zuerst sicherstellen, dass alle Daten korrekt geladen werden (mit einem kleinen Test), dann die HTML-Seite und das Design erstellen, und erst danach die Funktionalität implementieren. Diese “step by step” Herangehensweise erfordert aber Entwicklungserfahrung. Im Screenshot sieht man die direkte Aufforderung, immer nur einen Teil zu erzeugen (Erzeuge die Dateien index.html und style.css): LLMs haben immer begrenzte Output-Token, es kann sein, dass sie bei Antworten, wo sie mehr Token brauchen würden als im Output möglich sind, dann Teile mit […] angeben.
Ich glaube, dass man diese Kompetenzen auch Nicht-Programmierer:innen relativ zügig vermitteln kann. Die nötigen Grundlagen für strukturiertes Vibe-Coding wären absolut machbar in einer Summer School, einer Lehrveranstaltung oder einer kleinen Workshopreihe aufzubauen.
Nach der erfolgreichen Timeline-Implementation fragte ich Claude: Könnten wir daraus ein Annotationstool machen, mit dem Forscher:innen zusätzliche Daten zu den Briefen hinzufügen können? Diese Erweiterung bot die Möglichkeit, verschiedene Implementierungsebenen zu evaluieren, von einfachen Notizen bis hin zu komplexen Kollaborationsfeatures. Ein wichtiger Schritt meinerseits war dann, Komplexität rauszunehmen und den Fokus wieder auf die Kernfunktionen zu legen. Mein Prompt war “mache eine einfache Version ohne KI-Unterstützung, Kollaboration und ohne Visualisierung”, die von Claude vorgeschlagen wurden. Ein Modell wie Claude Sonnet 4 muss für solche Aufgaben nicht mehr aufwendig promptet werden. Das Prompting verändert sich also kontinuierlich mit den Modellen.
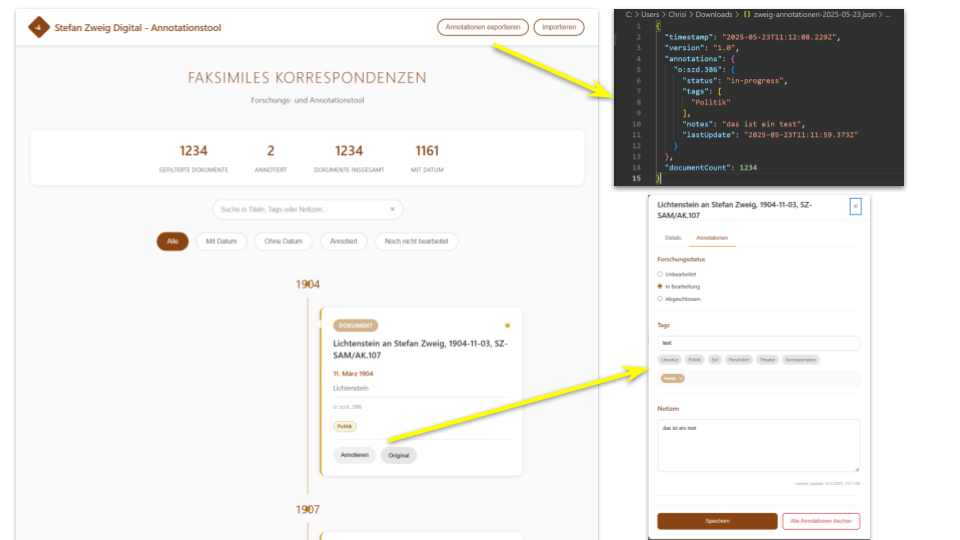
Das finale Tool ist vollständig browserbasiert und erfordert keine externen Abhängigkeiten. Annotationen werden lokal gespeichert und können als JSON exportiert werden. Daraus ließe sich eine pragmatische Lösung für die individuelle Forschungsarbeit ziemlich schnell umsetzen. Im konkreten Fall bleibt es jedoch ein Experiment.
“Das Spannende am Promptotyping ist, dass wir Werkzeuge bauen, ohne genau zu wissen, wohin sie uns führen. Die Technologie gibt uns Möglichkeiten – aber erst der Mensch mit Feingefühl und Intuition macht daraus etwas wirklich Wertvolles. Es braucht Mut, nicht alles kontrollieren zu wollen – und Klarheit darüber, wann genau das nötig ist. Promptotyping ist nur ein Instrument. Entscheidend ist, wer es benutzt, wie aufmerksam und wie offen er dabei ist. Die besten Ergebnisse entstehen nicht durch das perfekte Befolgen von Regeln, sondern genau an der Grenze zwischen Kontrolle und Loslassen. Dort liegt das Potenzial für echte Innovation – und bedeutende Forschung.”
So würde Rick Rubin vielleicht klingen, wenn man Claude Sonnet 4 beauftragt, ein Schlusswort für diesen Forschungsblog zu halluzinieren: mit dem Transkript seines Interview28 zu Vibe Coding im Context Window. Ganz im Geiste des Vibe Codings!
-
Nicht relevanter persönlicher Kommentar: Ich bin seit meiner Jugend großer SOAD und Nu Metal Fan ↩
-
Christopher Pollin. “Haters gonna hate”: Warum die Kritik an Vibe Coding berechtigt ist – und welche Proto-AGI-Potenziale sie übersieht. https://dhcraft.org/excellence/blog/Vibe-Coding ↩
-
Diese Spaltung schwächt möglicherweise genau die Kräfte, die als Gegengewicht zur Tech-Oligarchie fungieren könnten. ↩
-
Based on Lao Tzu. Adapted by Rick Rubin. THE WAY OF CODE. The Timeless Art of Vibe Coding. https://www.thewayofcode.com ↩
-
tante. ‘On “Vibe Coding”’. Smashing Frames (blog), 23 May 2025. https://tante.cc/2025/05/23/on-vibe-coding/. ↩
-
Christopher Pollin. Modelling, Operationalising and Exploring Historical Information. Using Historical Financial Sources as an Example. Dissertation. Universität Graz. 2025. ↩
-
Christopher Pollin. Promptotyping: Von der Idee zur Anwendung. Digital Humanities Craft, 24.04.2025. https://dhcraft.org/excellence/blog/Promptotyping/. CC BY 4.0. ↩
-
Chen, Wei, Zhen Huang, Liang Xie, Binbin Lin, Houqiang Li, Le Lu, Xinmei Tian, u. a. „From Yes-Men to Truth-Tellers: Addressing Sycophancy in Large Language Models with Pinpoint Tuning“. arXiv, 5. Februar 2025. https://doi.org/10.48550/arXiv.2409.01658. ↩
-
Lightman, Hunter, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. ‘Let’s Verify Step by Step’. arXiv, 31 May 2023. https://doi.org/10.48550/arXiv.2305.20050. ↩
-
https://dhcraft.org/excellence/promptotyping/szd-annotation-timeline ↩
-
“Kostenlos”. Man bezahlt nicht mit Geld, sondern mit seinen Daten und einem erhöhten CO2-Abdruck. ↩
-
Introducing Claude 4. https://www.anthropic.com/news/claude-4. The AI Daily Brief: Artificial Intelligence News. What to Use Claude 4 For. https://youtu.be/ukYjpCghCMM ↩
-
Wie immer gibt es ein ausgezeichnetes Video von Philip von AI Explained. Claude 4: Full 120 Page Breakdown … Is it the Best New Model? https://youtu.be/Xn_5aIhrJOE ↩
-
Alignment faking in large language models. https://youtu.be/9eXV64O2Xp8 und How difficult is AI alignment?. Anthropic Research Salon: https://youtu.be/IPmt8b-qLgk ↩
-
Anthropic’s Responsible Scaling Policy: https://www.anthropic.com/news/anthropics-responsible-scaling-policy ↩
-
Responsible Scaling Policy. Version 2.2. 2025. https://www-cdn.anthropic.com/872c653b2d0501d6ab44cf87f43e1dc4853e4d37.pdf ↩
-
https://www.anthropic.com/news/activating-asl3-protections ↩
-
Chemische, Biologische, Radiologische und Nukleare Waffen ↩
-
Anthropics Trainingsmethode, bei der Claude anhand expliziter Prinzipien trainiert wird, anstatt durch implizites menschliches Feedback. Die “Verfassung” umfasst Prinzipien aus der UN-Menschenrechtserklärung, Internationale Plattform-Richtlinien, nicht-westlichen Perspektiven und KI-Sicherheitsregeln. In Phase 1 lernt das Modell, eigene Antworten anhand dieser Prinzipien zu kritisieren und zu überarbeiten; in Phase 2 erfolgt Reinforcement Learning mit KI-generiertem statt menschlichem Feedback. Claude’s Constitution https://www.anthropic.com/news/claudes-constitution ↩
-
Hier findet man alle System Prompts der Claude-Modelle. https://docs.anthropic.com/en/release-notes/system-prompts ↩
-
Dario Amodei. The Future of U.S. AI Leadership with CEO of Anthropic Dario Amodei. https://www.youtube.com/live/esCSpbDPJik ↩
-
Dieses 5-stündige Interview mit Dario Amodei und der promovierten Ethikerin Amanda Askell, die für den „Charakter“ von Claude zuständig ist, finde ich persönlich überzeugend. Dario Amodei: Anthropic CEO on Claude, AGI & the Future of AI & Humanity. Lex Fridman Podcast. https://youtu.be/ugvHCXCOmm4?si=zZ3Tb5Tj4jiwXaPm ↩
-
Geisteswissenschaftliches Asset Management System. https://gams.uni-graz.at ↩
-
Individualisiertes Set domänenspezifischer Testfragen zur qualitativen Schnellbewertung von LLM-Verhalten und Prompt-Anpassungen ↩
-
The AI Daily Brief: Artificial Intelligence News. Rick Rubin on Art, Life, and Vibe Coding. https://youtu.be/6BDsFUvPqI0. ↩