

Vibe Coding als Hype – oder steckt mehr dahinter?
“Haters gonna hate” – oft wird Neues oder Unbekanntes aus Prinzip kritisiert. Genau hier setzt die aktuelle Debatte um „Vibe Coding“ an: Einerseits ist vieles an der Kritik dieser neuen Form der KI-gestützten Programmierpraxis absolut berechtigt, andererseits übersieht sie, aus meiner Sicht, technische, erkenntnistheoretische und soziale Implikationen, die bereits Proto-AGI-Potenziale andeuten – also erste Ansätze allgemeiner maschineller Intelligenz, die flexibel auf neue Probleme reagieren kann. Vibe Coding sollte daher nicht nur als kurzfristiger Hype verstanden werden – auch wenn es sich aktuell zweifelsfrei um einen virulenten Trend handelt –, sondern vielmehr als Indikator dafür, dass Frontier-LLMs zunehmend besser und stabiler darin werden, komplexe Problemstellungen effektiv zu bearbeiten.
Vibe Coding: „Einfach mal den Vibes folgen“ (Andrej Karpathy)
Der Begriff wurde im Februar 2025 von Andrej Karpathy, Mitbegründer von OpenAI, eingeführt. In einem Tweet beschreibt er diese KI-gestützte Programmierpraxis ironisch als Ansatz, bei dem man sich “ganz den Vibes hingibt”, sich exponentiellen Entwicklungen überlässt und sogar “vergisst, dass es den Code überhaupt gibt”. Karpathy nutzt hierfür Tools wie Cursor1 in Kombination mit Claude Sonnet 3.52 und kommuniziert über Superwhisper3 direkt mit dem LLM – er schreibt, dabei “kaum noch die Tastatur zu berühren”.
 Andrej Karpathy. Vibe Coding. https://x.com/karpathy/status/1886192184808149383
Andrej Karpathy. Vibe Coding. https://x.com/karpathy/status/1886192184808149383
Besonders charakteristisch ist Karpathys ironischer Umgang mit diesem neuen Ansatz: Er akzeptiert generierte Codeänderungen mittlerweile blind per “Accept All” und gibt Fehlermeldungen wortlos zurück an die KI – oft erfolgreich, aber nicht immer bewusst nachvollziehbar. Er selbst bringt es auf den Punkt: “Es ist nicht wirklich Programmieren – ich sehe Dinge, sage Dinge, führe Dinge aus und kopiere Dinge, und meistens funktioniert es”.
Karpathy ist nicht irgendwer: Er prägt die Entwicklung von KI-Technologien seit ihren Anfängen entscheidend mit und produziert zudem hervorragende Lehrvideos zu diesem Themenfeld.4 Bereits in den letzten Jahren formulierte er wesentliche Ideen wie “LLMs as Operating Systems”5 und “The hottest new programming language is English”6, die mögliche Entwicklungspfade hin zu einer tiefergehenden Integration von LLMs vorzeichnen und Perspektiven für zukünftige technologische Entwicklungen aufzeigen.
Vibe Coding bezeichnet einen KI-gestützten Programmieransatz, bei dem Aufgaben durch kurze Beschreibungen (Prompts) an ein LLM übertragen werden. Das Modell generiert daraufhin eigenständig den notwendigen Code. Die Rolle der Programmierenden verschiebt sich dadurch zunehmend von der manuellen Implementierung hin zu einer steuernden Tätigkeit, bei der KI-generierte Ergebnisse validiert, getestet und iterativ optimiert werden.
Diese Methode gewinnt zunehmend an Effizienz, insbesondere weil sogenannte Reasoning-Modelle, die nach dem Paradigma des Test-Time-Compute arbeiten7, immer besseren und umfangreicheren Code erzeugen. Der CEO von Anthropic Dario Amodei brachte diese Entwicklung kürzlich pointiert auf den Punkt: “Innerhalb von drei bis sechs Monaten wird KI bereits 90 Prozent des Codes generieren – und nach zwölf Monaten praktisch alles”.8 Wichtig hierbei ist hervorzuheben, dass Amodei explizit von Code-Generierung spricht, nicht vom Programmieren im herkömmlichen Sinne oder gar klassischer Softwareentwicklung. Aktuell liegt der Fokus eindeutig auf der automatischen Produktion großer Codemengen, während konzeptionelle Aspekte wie Softwarearchitektur und tiefgehende Entwicklungsarbeit noch zweitrangig sind.
Technische Schuld, Wartbarkeit und Sicherheit: Grenzen des Vibe Coding
Genau hier setzt berechtigte Kritik an: Technische Grenzen des Vibe Coding zeigen sich deutlich. KI-generierter Code weist häufig suboptimale Strukturen und ineffiziente Algorithmen auf, was insbesondere bei performancekritischen Anwendungen problematisch ist. Die fehlende tiefgehende Überprüfung durch menschliche Entwickler:innen („Expert in the Loop“) erhöht zudem das Risiko von Sicherheitslücken, vor allem in sensiblen Anwendungsbereichen. Ein typisches Beispiel ist die unkritische Installation von KI-vorgeschlagenen Python-Bibliotheken: So könnte eine KI empfehlen, zur farbigen Ausgabe von Text eine unbekannte Bibliothek (colorama-plus9 statt des legitimen Pakets colorama) zu installieren. Wird dieser Vorschlag unzureichend geprüft, könnten Entwickler:innen versehentlich Schadsoftware installieren oder sensible Daten gefährden.
Zudem entstehen Schwierigkeiten bei der Erweiterung komplexer Systeme, da LLM-generierter Code überwiegend isoliert entsteht und oft nicht ausreichend in bestehende Systemarchitekturen integriert ist. Die mangelnde Konsistenz architektonischer Entscheidungen über mehrere Entwicklungszyklen erschwert eine nachhaltige Weiterentwicklung. Das bedeutet jedoch nicht, dass umfangreichere, LLM-basierte Programmierumgebungen künftig nicht doch die Bewältigung höherer Komplexität ermöglichen könnten. Aufgrund dieser aktuellen Einschränkungen eignet sich Vibe Coding momentan primär für Prototypen oder unkritische Aufgaben in der Datenverarbeitung. Gleichzeitig bietet der Ansatz eindeutige Vorteile für alltägliche Aufgaben wie schnelle Datenanalysen, Visualisierungen, Datentransformationen oder einfache Skripte. Insbesondere temporäre, lokal genutzte Software ohne komplexe Backends oder APIs lässt sich aus meiner Sicht gut mit Vibe Coding realisieren und schafft hier unmittelbaren Mehrwert. Gezielt und kompetent eingesetzt, kann sich das anfänglich naive Vibe Coding zunehmend zu einem effektiven Vibe Engineering weiterentwickeln.
 Vibe Coding vs Vibe Engineering. https://www.reddit.com
Vibe Coding vs Vibe Engineering. https://www.reddit.com
Wenn “die KI” alles codet – was lernen wir dann noch?
Neben technischen Einschränkungen bestehen erhebliche erkenntnistheoretische Herausforderungen. Insbesondere stellen sich Fragen danach, wie ein solcher Zugang die Art verändert, in der Wissen im Bereich der Programmierung generiert, verstanden, vermittelt und angewendet wird. Die teilweise erheblichen Verständnislücken bezüglich der Implementierungslogik führen dazu, dass Entwickler:innen zunehmend Schwierigkeiten bekommen könnten, den KI-generierten Code eigenständig zu verändern, zu debuggen oder effektiv zu optimieren. Werden komplexe Implementierungsaufgaben regelmäßig an KI-Systeme übertragen, entsteht langfristig das Risiko eines schrittweisen Kompetenzverlusts, da bestimmte technische Fertigkeiten kaum noch aktiv angewandt werden. Hinzu kommt das Problem einer Kontrollillusion, bei der Entwickler:innen ihre tatsächliche Steuerungsfähigkeit über KI-generierten Code überschätzen und dadurch Risiken falsch einschätzen. Besonders kritisch erscheint die daraus resultierende Wissensfragmentierung, also eine zunehmende Kluft zwischen Anwendungswissen und Implementierungsverständnis. All diese Aspekte werfen grundlegende Fragen nach den langfristigen Auswirkungen auf geistige Fähigkeiten, Lernprozesse und die Fachkompetenz innerhalb der Entwicklungsgemeinschaft auf.
“The One Snake”
Dies deckt sich mit meinen eigenen Erfahrungen im Umgang mit Vibe Coding. Im dokumentierten Beispiel „The One Snake“ habe ich mithilfe von Claude 3.5 Sonnet ein vollständiges, funktionales Snake-Spiel ausschließlich über gezielte Prompts erstellt. Bereits nach dem initialen Prompt generierte Claude automatisch Design-Dokumente, eine Testsuite sowie ein visuell ansprechendes und funktionierendes User-Interface. Ein iterativer Debugging-Prozess lieferte zusätzlichen Kontext über das Programm und ermöglichte dadurch eine schnelle Fehlerbehebung. Eine der Iterationen der Test Suite ist hier abgebildet:
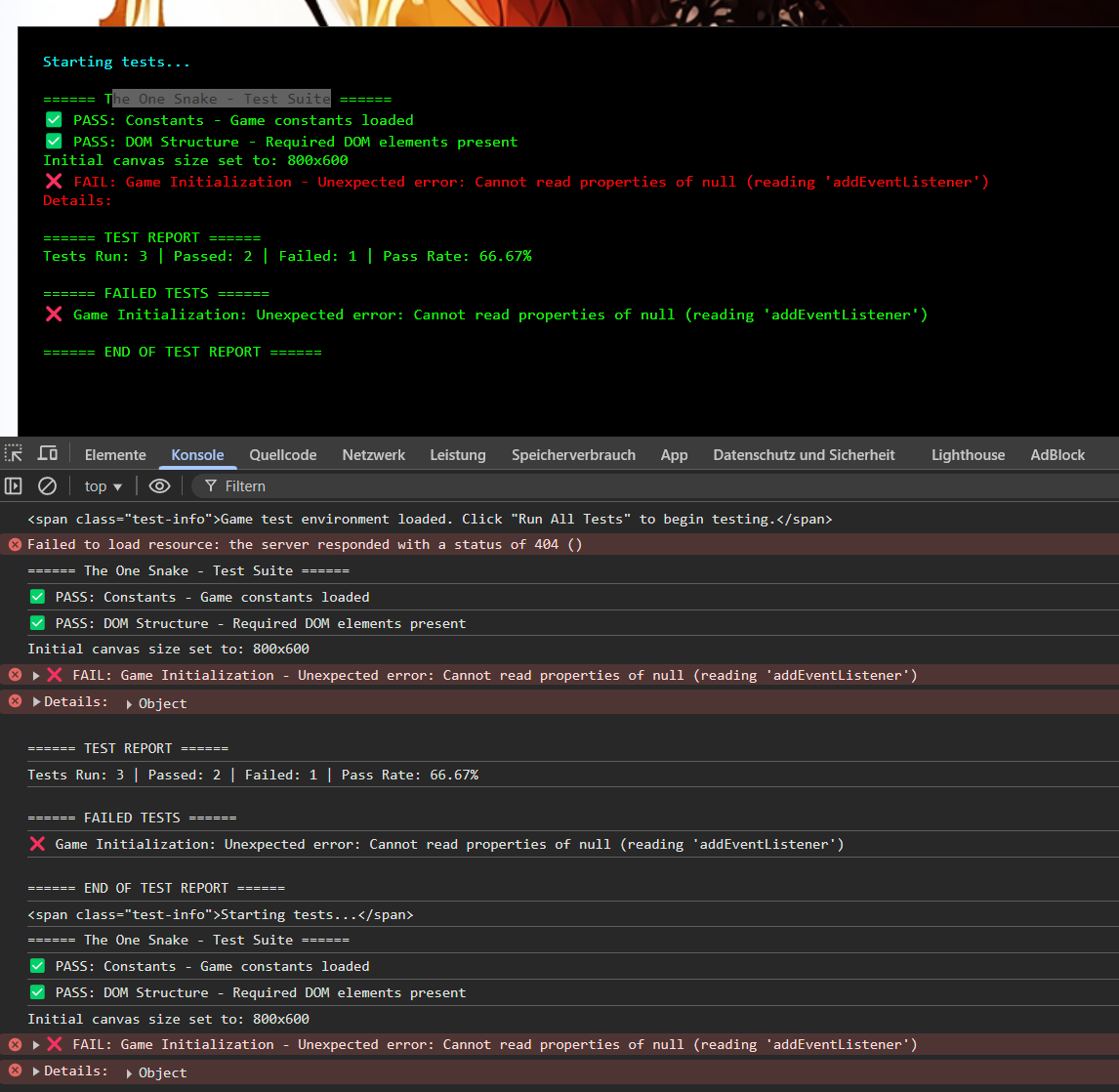
Dieses Beispiel zeigt: Einfachere Anwendungen lassen sich nahezu unmittelbar realisieren. Auch komplexere Aufgaben führen überraschend schnell zu funktionierenden Prototypen. Allerdings habe ich den generierten Code bisher gar nicht genauer analysiert – mir ist daher nicht bewusst, wie und warum das Spiel genau funktioniert. Dennoch funktioniert es.
Gleichzeitig verdeutlichen meine Experimente jedoch die aktuellen Grenzen des Vibe Coding: Je komplexer und umfangreicher die Software wird, desto schwieriger wird deren langfristige Weiterentwicklung. Mit zunehmender Komplexität führen das begrenzte Kontextfenster sowie inhärente Modellbeschränkungen dazu, dass die Software immer schwerer wartbar wird oder an ihre Grenzen stößt. Dennoch unterstreichen diese Erfahrungen das enorme Potenzial der Modelle und verdeutlichen zugleich, dass Vibe Coding aktuell noch in einer frühen Phase steckt. Es ist jedoch davon auszugehen, dass in den kommenden Monaten verbesserte Prompting-Strategien und Techniken entstehen werden, die diese Herausforderungen zunehmend minimieren.
“Ein Forschungstool einfach vibe coden”
Doch nicht nur bei einfachen und weit verbreiteten Anwendungen wie Snake, die vermutlich häufig in den Trainingsdaten der Modelle vorkommen, zeigt sich das Potenzial von Vibe Coding. Besonders spannend wird es vielmehr, wenn diese Methode gezielt auf konkrete wissenschaftliche oder domänenspezifische Fragestellungen angewandt wird. Durch den Einsatz von Frontier-LLMs eröffnen sich völlig neue Möglichkeiten, um Forschungstools direkt und unkompliziert aus Forschungsfragen und Daten zu entwickeln. Ich habe kürzlich mehrere Experimente durchgeführt, bei denen wir gemeinsam mit Partner:innen domänenspezifische, sofort einsatzfähige Prototypen praktisch direkt aus der Forschungsfrage heraus “gevibe-codet” haben. Diese extrem schnelle und flexible Vorgehensweise eröffnet nicht nur neue Wege im Requirements Engineering, sondern verändert maßgeblich die iterative Umsetzung im Forschungsprozess – inklusive aller Herausforderungen und Fallstricke. Natürlich sind solche rasch erstellten Tools meist noch keine fertigen Endprodukte, aber genau darin liegt ihre Stärke: Wir können unmittelbar experimentieren, testen und neue Lösungsansätze ausprobieren. Wenn man sich vom reinen „Vibe Coden“ löst und daraus eine strukturierte Methode entwickelt, könnte dieser Ansatz sogar noch besser funktionieren. Wir arbeiten aktuell genau an einer solchen Methode und nennen sie Promptotypen10 – dazu aber mehr in einem zukünftigen Blogbeitrag.
Proto-AGI incoming? Warum Vibe Coding mehr ist als bloße Code-Generierung
Unter Proto-AGI (proto-artificial general intelligence) verstehe ich Systeme, die zwar noch keine vollständige Allgemeine Künstliche Intelligenz11 darstellen, aber bereits zentrale Eigenschaften einer AGI in rudimentärer Form besitzen. Typischerweise bedeutet dies, dass ein LLM nicht nur spezialisierte Aufgaben löst, sondern eigenständig komplexe Problemstellungen generalisiert, selbstständig transferiert und dabei adaptiv auf unbekannte Szenarien reagieren kann. Im Gegensatz zu aktuellen spezialisierten Modellen zeichnen sich Proto-AGI-Systeme durch höhere Autonomie, robustere Abstraktionsfähigkeit und tiefere, generalisierte Problemlösungskompetenzen aus.
Beim Vibe Coding generieren Modelle nicht bloß einzelne Code-Snippets, sondern sind in der Lage, komplexe und abstrakte Anforderungen aus vagen Beschreibungen (“Vibes”, also informelle, sprachliche Anweisungen) heraus zu strukturieren, konzeptuell zu erfassen und in funktionalen, lauffähigen Code umzusetzen.12 Dabei zeigen Frontier-LLMs bereits Ansätze zentraler Proto-AGI-Merkmale, insbesondere die Fähigkeit zu abstraktem Transferlernen, indem sie einmal gelernte Prinzipien eigenständig auf neue Problemstellungen übertragen, autonome Problemzerlegung komplexer Anforderungen in logische Teilprobleme, sowie adaptive Anpassung durch selbstständige Fehlerkorrektur und iterative Optimierung. Ein konkretes Beispiel für solche Proto-AGI-Ansätze ist etwa die Fähigkeit eines Modells wie Claude 3.7 Sonnet, aus einem bereits gut gefüllten Context Window selbstständig die Rolle eines Prompt Engineers einzunehmen und daraus systematisch einen optimierten Systemprompt für ein weiteres LLM abzuleiten – eine Aufgabe, die deutlich über reine Mustererkennung hinausgeht und eine erste Form der generalisierten Problemlösungsfähigkeit andeutet.
Gerade diese Fähigkeiten entsprechen Kernmerkmalen, die für Proto-AGI-Systeme charakteristisch sind. Natürlich sind heutige Modelle wie Claude 3.7 Sonnet noch nicht vollständig autonom, allgemein intelligent oder gar auf menschlichem Niveau. Jedoch deuten Multi-Agenten-Systeme13, die auf dieser Modellgeneration basieren, bereits an, wie Proto-AGI-Systeme künftig aussehen könnten. Besonders entscheidend ist hierbei die Fähigkeit, nicht bloß einzelne Programmieranweisungen auszuführen, sondern – durch geeignete Prompts angestoßen – eigenständig Strategien zur Problemlösung und Optimierung zu entwickeln. Weiterentwickelte Modelle, die etwa mittels Reinforcement Learning14 oder in Multi-Agenten-Architekturen autonom ihre Prompt-Strategien und Problemlösungskompetenzen verbessern, könnten schon bald wesentliche Schritte in Richtung Proto-AGI vollziehen.
Coding 2.0: Vom Programmieren zum Orchestrieren, Wissen und Spezifizieren?
Um die tatsächlichen Potenziale des Vibe Codings auszuschöpfen und gleichzeitig bestehende Risiken wie technische Schuld, Wartbarkeit und Kompetenzverlust wirksam zu begrenzen, braucht es eine systematische Integration in hybride Entwicklungsprozesse. Konkret bedeutet das: verbessertes Requirements Engineering, sorgfältiges und systematisches Prompt Engineering, spezielle Workflows und Tools, die die Nachvollziehbarkeit und Qualität der generierten Software erhöhen, sowie konsequente Review- und Testverfahren. Momentan befindet sich Vibe Coding noch in einer explorativen Phase, könnte sich aber mittelfristig in stabilere Workflows überführen lassen.
Es zeichnet sich ab, dass klassische Programmierkompetenzen (Coding 1.0) zunehmend durch neue Kernfähigkeiten (Coding 2.0) ersetzt werden: Prompt-Engineering, Anforderungsanalyse und Validierung rücken in den Fokus. Laut Dario Amodei könnten LLM schon in wenigen Monaten bis zu 100 % des Codes generieren. Zugleich entstehen Herausforderungen: Zentralisierung und Marktmacht großer KI-Unternehmen (OpenAI, Anthropic, Google) bedrohen kleinere Akteure. Die versprochene “Demokratisierung” der Entwicklung bleibt fraglich, da effektives Vibe Coding weiterhin substanzielle Expertise (“Expert in the Loop”) voraussetzt. Zudem bestehen erhebliche langfristige Risiken bezüglich Wartbarkeit und Stabilität komplexer KI-generierter Systeme. Vibe Coding verlangt daher bewusstes strategisches Vorgehen, kritische Reflexion und neue Kompetenzen.15
Lerne zu lernen – aber anders als bisher: Es wird künftig weniger darum gehen, traditionell zu programmieren, sondern vielmehr darum, KI-Tools reflektiert und bewusst einzusetzen. Gerade weil diese Tools immer näher an Proto-AGI-Fähigkeiten heranrücken, ist es entscheidend, nicht blind auf KI-generierten Code zu vertrauen und das Verständnis für grundlegende Programmierprinzipien zu erhalten. Frage dich deshalb regelmäßig ehrlich, ob du wirklich noch verstehst, was gerade passiert.
-
Cursor ist eine KI-gestützte IDE auf Basis von VS Code, die mithilfe von LLMs Codevervollständigung, Chat-basierte Assistenz und kontextsensitive Codegenerierung bietet, um komplexe Aufgaben zu vereinfachen und den Entwicklungsworkflow zu optimieren. https://docs.cursor.com/get-started/welcome ↩
-
Modell der Firma Anthropic. https://www.anthropic.com/news/claude-3-5-sonnet ↩
-
Superwhisper ist eine lokale, KI-basierte Sprach-zu-Text-App, die Spracheingabe in beliebigen Anwendungen ermöglicht, Transkriptionen erstellt und Übersetzungen unterstützt. https://superwhisper.com ↩
-
Andrej Karpathy. Deep Dive into LLMs like ChatGPT. https://youtu.be/7xTGNNLPyMI. Andrej Karpathy. [1hr Talk] Intro to Large Language Models. https://www.youtube.com/watch?v=zjkBMFhNj_g. Andrej Karpathy. How I use LLMs.https://youtu.be/EWvNQjAaOHw. Andrej Karpathy. Let’s build the GPT Tokenizer. https://youtu.be/zduSFxRajkE ↩
-
Hier sind einige meiner Ausführungen zu Reasoning-Modellen und Test Time Compute. https://dhcraft.org/excellence/blog/New-Year-New-AI-IdeaLab-25 ↩
-
Paraphrisiert. Dario Amodei: “The Future of U.S. AI Leadership with CEO of Anthropic Dario Amodei.” https://www.youtube.com/live/esCSpbDPJik ↩
-
Eine fiktive Python-Bibliothek als Beispiel. Grundsätzlich kann jede Person Python-Bibliotheken auf PyPI (dem Python Package Index) veröffentlichen. ↩
-
OpenAI definiert Artificial General Intelligence (AGI) als KI-Systeme, die in der Lage sind, Menschen bei den meisten ökonomisch relevanten Aufgaben zu übertreffen. Diese Definition ist allerdings unzureichend. ↩
-
Unter Programmsynthese versteht man den automatischen Prozess, bei dem ausführbarer Programmcode aus abstrakten, formellen oder informellen Beschreibungen generiert wird. Beim Vibe Coding geschieht dies speziell durch LLM, die informelle, sprachliche Anweisungen (“Vibes”) in funktionalen, lauffähigen Code übersetzen. Diese Praxis entspricht François Chollets Definition intelligenter Systeme als solche, die durch Generalisierung und Abstraktion eigenständig neue Programme synthetisieren, um bisher unbekannte Probleme zu lösen. Exploring Program Synthesis: Francois Chollet, Kevin Ellis, Zenna Tavares. https://youtu.be/TQDCsyuuwsg ↩
-
Multi-Agenten-Systeme (MAS) bezeichnen Systeme, in denen mehrere KI-Agenten parallel, iterativ oder sequenziell miteinander kommunizieren und kooperieren, um Aufgaben gemeinsam zu lösen. Jeder Agent (typischerweise eine Serie von Prompts an ein LLM, ergänzt um spezifische Tools) handelt dabei weitgehend autonom und verfügt über eigene Teilziele, Fähigkeiten und Wissensbestände. Entscheidend für die Effektivität von MAS ist die koordinierte Interaktion und gegenseitige Validierung der Agenten. Aktuelle Beispiele sind Claude Code, bei dem mehrere KI-Agenten parallel Software entwickeln, testen und validieren, sowie OpenAI Deep Research, das autonome Agenten orchestriert, um komplexe Rechercheaufgaben durch gegenseitige Überprüfung der Ergebnisse zuverlässiger zu bearbeiten. ↩
-
Reinforcement Learning (RL) für Reasoning-Modelle bezeichnet einen Trainingsansatz, bei dem erfolgreiche Reasoning-Strategien durch gezielte Belohnungen verstärkt werden. Dabei wird insbesondere die Qualität sogenannter „Chain-of-Thought“-Denkpfade optimiert. RL bildet derzeit eine Kerntechnologie in Modellen wie o1. ↩
-
The AI Daily Brief: Artificial Intelligence News. Should Anyone Learn to Code Anymore?. https://youtu.be/fXfFE_22wNU ↩