
AI Monopoly
Das Brettspiel Monopoly hat ein klares Ziel: durch strategischen Immobilienkauf, Bebauung und Mieteinnahmen zur reichsten Spielerin zu werden. Eine ähnliche Strategie verfolgen im Jahr 2025 die großen Technologiekonzerne - oder genauer: die Tech-Oligarchen (alles Männer!). OpenAI, Microsoft, Google, Meta, Anthropic, Nvidia und xAI bauen systematisch ihre Monopole im Bereich des “Reasoning” aus – eine Schlüsselfähigkeit zukünftiger KI-Systeme. Sie skalieren ihre Sprachmodelle durch den Kauf und die oft fragwürdige Aneignung von Daten, unterstützt durch Milliardeninvestitionen in Rechenleistung (“Stargate”).1 Sie kassieren dabei Gebühren von den Nutzer:innen. Doch trotz dieser Einnahmen machen viele Unternehmen erhebliche Verluste (außer Nvidia), wie ein Tweet von Sam Altman2 zeigt: Selbst das ChatGPT Plus-Abonnement für 200 $ im Monat führt zu roten Zahlen. Moralische Fragen, vor allem zum Umgang mit Daten, bleiben meist unbeantwortet und scheinen selten Konsequenzen zu haben – oder man kauft sich wie bei Monopoly einfach frei.
Ich möchte aufzeigen, warum Generative KI in naher Zukunft weit über die allgemeinen Erwartungen hinausgehen wird; warum die vorherrschenden Vorstellungen aus meiner Sicht fehlgeleitet sind und warum die Tech-Konzerne bereits heute ein Monopol auf die strategische Ressource “Reasoning” besitzen. Eine überraschende Wendung bringt dabei die chinesische Firma DeepSeek: Sie ist gerade “über Los gegangen” und hat sich die symbolischen “200 $” gesichert, indem sie mit R1 qualitativ hochwertiges KI-Reasoning als Open Source und zu erschwinglichen Preisen verfügbar macht (was wohl eher als bewusste Aktion des autokratischen Staates China zu verstehen ist).3
Was kann ein LLM eigentlich?
Zuvor sollten wir uns dem überstrapazierten Begriff “Reasoning” widmen.4 LLMs unterscheiden sich grundlegend von menschlicher Intelligenz. Ein direkter Vergleich ist daher wenig zielführend – wir haben es mit etwas grundsätzlich Neuem zu tun. Welche Fähigkeiten und Grenzen haben die modernsten Large Language Models – die sogenannten Frontier-LLMs?
LLMs weisen systematische Verzerrungen (Bias) auf, die durch Trainingsdaten und menschliches Feedback während des (Post-)Trainings entstehen. Diese Verzerrungen spiegeln gesellschaftliche Vorurteile wider und treten in verschiedenen Formen auf. Die Leistungsfähigkeit der LLMs hängt dabei stark von der Menge und Qualität der verfügbaren Trainingsdaten ab: Je häufiger bestimmte Muster in den Daten vorkommen, desto besser werden sie verarbeitet, während seltenere Muster deutlich schlechter funktionieren. Dies zeigt sich beispielsweise darin, dass gendergerechte Texte oft in maskuline Form überführt werden oder amerikanisches Englisch gegenüber britischem bevorzugt wird. Durch gezieltes Prompting lassen sich diese Verzerrungen jedoch korrigieren.5
LLMs zeigen zudem oft unerwartetes Verhalten: Sie reagieren auf sprachliche Aspekte wie Höflichkeit und grammatikalische Komplexität sowie auf soziale Konventionen wie Trinkgeld.6 Diese Reaktionen entstehen, weil entsprechende Muster in den Trainingsdaten existieren und durch menschliches Feedback im Post-Training – bewusst oder unbewusst – verstärkt werden. Ein interessantes Beispiel für eine bewusst implementierte Verzerrung zeigt sich am “Character von Claude”, der durchgängig konstruktiv und freundlich agiert.7
LLMs halluzinieren – das bedeutet, sie generieren falsche Inhalte. Dies hat zwei Seiten: Einerseits können dadurch kreative, neuartige Lösungen entstehen, andererseits können auch faktisch falsche oder irreführende Aussagen produziert werden. Halluzinationen sind dabei nicht nur als Nachteil zu sehen, sondern stellen eine fundamentale und derzeit notwendige Eigenschaft von LLMs dar. Die zentrale Herausforderung liegt darin, diese Halluzinationen bewusst und kontrolliert zu nutzen. Ein hilfreicher Ansatz ist es, grundsätzlich alle Ausgaben eines LLM als potenziell halluziniert zu betrachten – sie erlangen erst dann Validität, wenn sie durch menschliche Überprüfung (“Human in the Loop”) oder etablierte Verifizierungsprozesse bestätigt wurden.8
Ein LLM kann räumliche und zeitliche Konzepte nur auf Basis von textuellen Beschreibungen verarbeiten, besitzt aber kein grundlegendes Verständnis für räumliche Dimensionen oder zeitliche Zusammenhänge. Die Welt kann man nicht nur durch Text lernen – eine Einsicht, die Yann Lecun, KI-Chef von Meta, prägnant auf den Punkt bringt: Eine Katze verfügt über ein komplexeres räumliches Verständnis als jedes aktuelle KI-System, weil sie Raum und Zeit aktiv erlebt und erfahren hat. LLMs werden zwar mit Texten, Bildern und Videos über räumliche und zeitliche Konzepte trainiert, können diese aber nie wirklich “erleben”. Dadurch bleiben viele für Menschen triviale räumliche oder zeitliche Probleme für KI-Systeme eine große Herausforderung.9
Die ARC-Benchmark10 (Abstraction and Reasoning Corpus) gilt als “Kompass für AGI” (AGI = Artificial General Intelligence), wie ihr Entwickler François Chollet sie bezeichnet. Sie stellt besonders die Fähigkeit zur Generalisierung und Problemlösung in den Vordergrund. Der Benchmark besteht aus einer umfangreichen Sammlung von Aufgaben mit bekannten Lösungen. In einem kontrollierten Setting lässt sich messen, wie gut ein LLM diese Aufgaben bewältigt – wobei zu beachten ist, dass Benchmarks generell mit verschiedenen methodischen Herausforderungen verbunden sind.
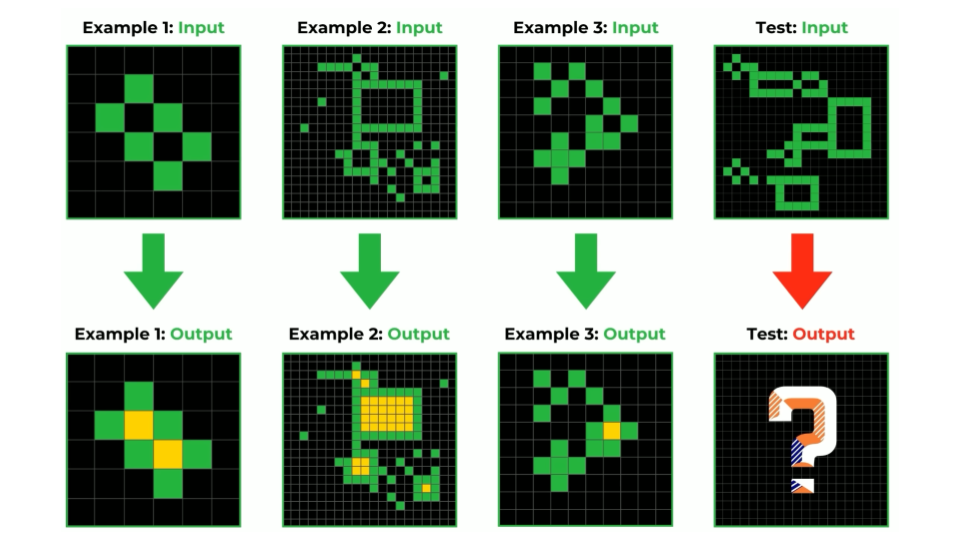
Die ARC-Benchmark zeigt, wie Menschen und KI-Systeme mit abstraktem Denken umgehen. Im gezeigten Beispiel sehen wir vier Bildpaare, von denen die ersten drei als Lernbeispiele dienen. Die Aufgabe besteht darin, aus grünen Pixelmustern eine bestimmte Transformation zu erkennen und diese auf ein neues, unbekanntes Muster anzuwenden. Was den ARC-Test so besonders macht: Er testet nicht das Wiedererkennen bekannter Muster, sondern die Fähigkeit, aus wenigen Beispielen neue Regeln abzuleiten – eine Kernkompetenz menschlicher Intelligenz. Der Test ist bewusst so angelegt, dass er ohne ein wirkliches Verständnis der zugrunde liegenden Prinzipien nicht gelöst werden kann. Ein reines “Pattern Matching”, wie es viele KI-Systeme beherrschen, reicht hier nicht aus. Das Fragezeichen im letzten Ausgabebild symbolisiert treffend die zentrale Herausforderung: Können KI-Systeme wirklich abstrahieren und Schlussfolgerungen ziehen?
LLMs sind (scheinbar) in der Lage, prozedurales Wissen aus engen Domänen zu adaptieren – sie lernen nicht nur Antworten (“Faktenwissen”) auswendig, sondern speichern und wenden Arbeitstechniken an, allerdings nur innerhalb eng verwandter Probleme und ohne wirklich übertragbares Verständnis. Ein persönlicher Vergleich verdeutlicht dies: Wie früher in Mathematik konnte ich auswendig gelernte Lösungswege auf neue Zahlenkombinationen und Varianten anwenden. Sobald jedoch ein grundlegend neues Problem auftauchte, das echtes Verständnis erforderte, scheiterte dieser Ansatz. LLMs operieren ähnlich – sie kombinieren “Auswendiglernen” mit einem scheinbaren “Verstehen und Anwenden von Grundprinzipien”, beides jedoch nur innerhalb enger Grenzen und ohne echtes tiefes Verständnis. Sie memorieren sowohl Inhalte als auch bestimmte Verarbeitungsmuster.11
Um das Reasoning-Verhalten von LLMs besser zu verstehen, ist ein Vergleich mit etablierten Modellen menschlichen Denkens hilfreich. Besonders aufschlussreich ist dabei Daniel Kahnemans12 Unterscheidung zwischen System 1 (schnelles, intuitives Denken) und System 2 (langsames, analytisches Denken). Bezogen auf Kahnemans Modell arbeiten LLMs im Sinne von System 1: Auf die Frage “2+2=” folgt unmittelbar die Antwort “4” – eine automatische Reaktion ohne tieferes Nachdenken. Dies entspricht der grundlegenden Funktionsweise von LLMs (Transformer und Next-Token-Prediction). System 2 hingegen würde bei einer mathematischen Aufgabe wie 2467 * 387 bewusst verschiedene Lösungswege analysieren, Annahmen überprüfen und Alternativen abwägen – vergleichbar damit, wie wir Menschen eine Multiplikation im Kopf durchführen, einschließlich der Möglichkeit, uns dabei zu verrechnen. Dies erfordert echtes Reasoning: ein bewusstes Nachdenken über Problem und Lösung. Die zentrale Frage ist, ob und inwieweit dieses System 2 überhaupt auf KI-Systeme übertragbar ist. Während System 1 sofortige Antworten liefert, erfordert System 2 eine schrittweise, überlegte Herangehensweise – selbst bei vergleichsweise einfachen Rechenaufgaben.
Wichtig zu verstehen ist: Wenn ein LLM “2+2=” beantwortet, führt es keine Rechenoperation durch, sondern ruft eine memorierte Lösung ab. Allerdings können LLMs externe Tools wie einen Taschenrechner aufrufen, um tatsächliche mathematische Operationen durchzuführen.
Reasoning durch Prompt Engineering: Chain of Thought und smartGPT
François Chollet, ein ehemaliger Google-Forscher, hat kürzlich eine neue Firma gegründet, die sich vermutlich der Programmsynthese widmen wird – der Entwicklung von KI-Systemen, die selbstständig Programme zur Problemlösung erstellen können. In diesem Kontext hat sich Chollet, bekannt für seine kritische und wissenschaftlich fundierte Arbeitsweise, mit der grundlegenden Frage auseinandergesetzt, was Intelligenz eigentlich ist. Seine Definition: Intelligenz ist die Fähigkeit eines Systems, neue Kompetenzen zu erwerben, um Situationen besser zu bewältigen. Dies geht über das bloße Auswendiglernen und Anwenden von Methoden hinaus – es bedeutet, sich aktiv neue Fähigkeiten anzueignen, um Probleme zu verstehen und unbekannte Situationen zu meistern. Diese Auffassung von Intelligenz als adaptive Lernfähigkeit bildet auch die Grundlage für seine Entwicklung der ARC-Benchmark, die genau diese Adaptionsfähigkeit testet.
Reasoning definiert Chollet als die Fähigkeit, bekannte Lösungsmuster anzuwenden, Probleme durch kreative Rekombination zu lösen und Entscheidungen durch Pattern-Matching und Wissenskomponenten auch in neuartigen Situationen zu treffen. Diese Definition ist sicherlich nicht vollständig, und über den Begriff der Intelligenz lässt sich trefflich streiten. Entscheidend ist jedoch, dass es für diese Begriffe keine absoluten Definitionen gibt, sondern nur Annäherungen.13
Mein Zugang zu dieser Thematik ist bewusst pragmatisch: LLMs betreiben kein menschliches Reasoning, sondern nutzen einen eigenständigen Mechanismus, den wir als “Token-basiertes Reasoning” bezeichnen können. Aus meiner Erfahrung als Prompt Engineer beschreibt dieser Begriff einen spezifischen Prozess: Ein LLM baut durch sequentielle Token-Generierung einen Kontext auf, der hilft, schrittweise bessere Antworten zu generieren. Denn LLMs sind zwar schwächer im sofortigen Generieren korrekter Antworten, aber stärker in der Überprüfung von bereits generiertem Kontext.14 Entscheidend wäre, dass wir diesen Mechanismus als eigenständiges Phänomen verstehen und beschreiben, statt ihn ständig am menschlichen Reasoning zu messen.
Diese Sicht auf Token-basiertes Reasoning wird durch eine bemerkenswerte These von Ilya Sutskever gestützt: Der Kernmechanismus von LLMs - die kontextbasierte Vorhersage des nächsten Tokens - ist möglicherweise tiefgreifender als bisher angenommen. Seine provokante Frage lautet: Was bedeutet es, das “richtige” nächste Token zu bestimmen? Seine Hypothese: Ein Modell, das dies konsistent leistet, muss sowohl den Kontext als auch die zugrundeliegende Realität in gewisser Weise “verstanden” haben.15
Reasoning durch Test Time Inference
Reasoning für LLMs bedeutet ausreichend Tokens zu generieren, damit ein KI-Sprachmodell genügend Kontext hat, um die Qualität seiner eigenen Antworten besser zu prüfen.
Diese Fortschritte basieren wesentlich auf Prompt Engineering, wobei “Chain of Thought” (CoT) die wichtigste Technik darstellt. Die Anweisung “let’s think step by step” erwies sich als emergente Eigenschaft ausreichend großer Sprachmodelle: Ein LLM zerlegt dabei komplexe Probleme in Teilschritte, analysiert diese einzeln und führt sie zur Lösung des Gesamtproblems zusammen. Diese Fähigkeit, die erst bei der Hochskalierung der Modelle entdeckt wurde, verbessert nachweislich die Ergebnisse bei Reasoning-Tasks und anderen Aufgaben erheblich. LLMs benötigen diese schrittweise Kontextgenerierung, um präzisere und zielgerichtetere Antworten zu generieren. Die CoT-Methodik lässt sich noch erweitern, etwa durch ‘Tree of Thought’, bei dem parallel mehrere Lösungspfade simuliert werden, oder durch PRISM, meine eigene Entwicklung, die die Leistung von Modellen wie Claude 3.5 Sonnet für spezifische Aufgaben weiter steigert. Die Details zu PRISM werde ich in einem gesonderten Blogpost erläutern.
Eine neue Generation von Modellen – manche sagen, es sei nichts Neues, manche nennen sie Reasoning-Modelle – verfolgt einen anderen Ansatz. Es sind die sogenannten o1-Modelle (OpenAI war die erste Firma, die diese Modelle ausgeliefert hat). Ihr Prinzip: Je mehr Token erzeugt werden, desto mehr vielversprechende Möglichkeiten entstehen und desto besser lassen sich die gelungenen Teile einer Antwort zusammenführen. Das bedeutet, zur Inferenz-Zeit – also während ein Modell gerade die Antwort erzeugt - werden viele “let’s think step by step”-Pfade generiert. Soweit man das angesichts der mangelnden Transparenz der Unternehmen verstehen kann, wurde CoT direkt in diese Modelle hinein trainiert. Dieser Ansatz nennt sich Test-Time-Compute und scheint skalierbar zu sein: Je mehr Rechenleistung zur Verfügung steht, desto bessere Ergebnisse erzielen die Modelle. Test-Time-Training erweitert diesen Ansatz - das Modell erlernt während der Problembearbeitung neue Parameter und adaptiert sich “on the fly”. Das Bild zeigt die von DeepSeeks R1 generierten Token. Das Modell zeigt die echten “Thinking Token”, anders als o1.

Prompt Engineering ist also absolut zentral für LLMs: Erkenntnisse aus dieser Technik werden direkt in neue Modelle integriert, während Test-Time-Compute als möglicherweise noch bedeutendere Skalierungshypothese erscheint.
o1 und R1
Laut François Chollet ist o1 ein natürlichsprachlicher Suchprozess, der den gesamten Raum möglicher Chain-of-Thought-Lösungen zu einem Input durchsucht und evaluiert, um die bestmögliche Lösung zu finden. Die verfügbare Rechenzeit bestimmt dabei die Intensität der Suche. Es werden verschiedene “let’s think step by step”-Pfade generiert, und es muss einen (bei o1 nicht öffentlich bekannten) Mechanismus geben, der die besten Pfade mit den vielversprechendsten Lösungen identifiziert. Das bedeutet nicht, dass die Ergebnisse immer perfekt sind, aber insgesamt erzielen die Modelle bessere Resultate und halluzinieren weniger. Diese Leistungssteigerung geht allerdings mit erheblichen Kosten für Stromverbrauch und Computerchips einher.
Ein bedeutender Durchbruch der letzten Tage ist die Veröffentlichung eines Reasoning-Modells durch DeepSeek, das qualitativ mit o1 vergleichbar ist, aber zu deutlich niedrigeren Kosten betrieben werden kann. Dies könnte 2025 weitreichende Auswirkungen haben. Daraus ergeben sich mehrere Schlussfolgerungen:16
- China liegt technologisch nicht weit hinter den USA zurück, und wir werden ein verstärktes KI-Wettrüsten erleben – wenn die Tech-Konzerne kein Monopol auf Reasoning haben, wird dies die USA übernehmen.17
- Je billiger und besser dieses Reasoning wird, desto eher werden fortgeschrittene KI-Produkte auf den Markt kommen und den Druck auf alle proprietären Anbieter erhöhen, die Preise zu senken und/oder die Systeme effizienter zu machen.
- R1 in seinen Varianten ermöglicht lokalen Betrieb. Organisationen, die ihre internen Daten nicht auf amerikanische Server übertragen wollen, können nun eigene Systeme aufbauen. Während dies theoretisch auch mit Metas Llama-Modellen möglich war, benötigten diese erhebliche GPU-Ressourcen. Die R1-Versionen hingegen erreichen auch in kleineren Konfigurationen bemerkenswerte Leistungen. Insbesondere Universitäten sollten sich auf diese lokalen Lösungsansätze konzentrieren.
- Open-Source-Entwicklung erweist sich hier als treibende Kraft für Innovation und Demokratisierung der KI-Technologie. Oder: zur Kapitalisierung und als Werkzeug autoritärer Staaten.
o3 “crushes benchmarks designed to stand for decades”
“o3 crushes benchmarks designed to stand for decades” ist ein direktes Zitat von Philip von AI Explained.18
o3, die Weiterentwicklung von o1, erreicht bemerkenswerte Leistungen bei etablierten Benchmarks. Besonders beeindruckend sind die Ergebnisse bei FourierMath, einem Test mit Aufgaben, die selbst Mathematikprofessor:innen mehrere Tage zur Lösung benötigen. Auch in den Naturwissenschaften und bei Programmieraufgaben erzielt o3 außergewöhnliche Resultate. Bemerkenswert ist das Ergebnis von 75.7% auf der ARC-Benchmark, die speziell zur Messung der Adaptionsfähigkeit bei neuartigen Aufgaben konzipiert wurde.
Fazit: New Year, New AI? → Yes!
New Year, New AI? Diese Frage lässt sich klar mit “Ja” beantworten. Die Entwicklung neuer Modelle wie o1 und o3 zeigt, dass sich “Reasoning” in KI-Systemen durch Test-Time-Compute und Test-Time-Training weiter skalieren lässt. Diese Ansätze ermöglichen eine Art “Reasoning auf Abruf”, bei dem ein Sprachmodell während der Anwendung kontinuierlich Tokens generiert und sogar während der Ausführung dazulernt. Das Resultat ist ein “Token-basiertes Reasoning” – kein echtes menschliches Denken oder Bewusstsein, aber in spezifischen, komplexen Bereichen erstaunlich leistungsfähig. Bezeichnend ist: Diese Systeme werden 2025 vermutlich Forschende bei komplexen Aufgaben unterstützen können, während sie an vermeintlich einfachen Aufgaben wie dem Ausfüllen eines SAP-Reiseantrags scheitern.
Die Folgen dieser Entwicklung sind weitreichend. Wir erleben bereits eine teilweise Automatisierung der Codegenerierung – wohlgemerkt nicht der gesamten Softwareentwicklung. Die verbesserten Planungsfähigkeiten dieser Reasoning-Modelle werden neuartige KI-Agenten ermöglichen, die eigenständig Probleme bearbeiten. Ob und wann wir zu echtem “Reasoning”, echter KI oder gar AGI gelangen, bleibt offen. Bemerkenswert ist der Wandel in der Kommunikation der Tech-Firmen: Während man im Herbst noch zurückhaltend war, dominiert nun selbstbewusstes Auftreten.
Gerade deshalb ist die Rolle der Expert:innen im Loop entscheidend. Im Jahr 2025 – und darüber hinaus – bleibt menschliche Expertise unverzichtbar für die Prüfung und verantwortungsvolle Nutzung von KI. Dies erfordert kontinuierliches Lernen, kritisches Denken, ethisches Handeln und die Akzeptanz eines fundamentalen Paradigmenwechsels. Wer mit diesen Technologien arbeitet, muss bereit sein zu lernen, zu experimentieren und offen über Chancen wie Risiken zu diskutieren. Das Monopol darf nicht den Tech-Oligarchen überlassen werden.
Christopher Pollin - Digital Humanities Craft
-
Bester Überblick: AI Explained. Nothing Much Happens in AI, Then Everything Does All At Once https://www.youtube.com/watch?v=FraQpapjQ18\&t=2s ↩
-
DeepSeek-R1 Release. https://api-docs.deepseek.com/news/news250120
Sam Witteveen gibt einen guten Überblick über das R1 Modell von DeepSeek https://youtu.be/gzZihJ5miZE?si=mWdD8NvG-O-Gaq81 ↩ -
Ein weitere Blick auf “Reasoning”: DO REASONING MODELS ACTUALLY SEARCH?. https://youtu.be/2xFTNXK6AzQ?si=Lg67ylgk3EqwpWcJ ↩
-
Diese Beobachtung basiert auf meiner persönlichen Erfahrung: Bestimmte Muster sind in den Trainingsdaten so stark repräsentiert, dass LLMs dazu neigen, immer wieder darauf zurückzufallen. Ein Beispiel ist amerikanisches Englisch: Das LLM tendiert dazu, andere Varianten des Englischen in amerikanisches Englisch umzuwandeln. Ein zweites aufschlussreiches Beispiel zeigt sich bei bekannten Rätseln: Wird beim klassischen Rätsel vom ‘Bauer mit Fuchs, Ziege und Kohl’ nur das Vokabular ausgetauscht, ist das ursprüngliche Lösungsmuster so stark eintrainiert, dass das Modell Schwierigkeiten hat, es zu generalisieren. ↩
-
“Kurios und faszinierend”. Prompt Engineering als Arbeits- und Forschungsmethode. https://docs.google.com/presentation/d/1iQRdf96BT4OS_Ayr82IoaQiW-WV28L48hm628ClPVIM/edit?usp=sharing ↩
-
Ich empfehle wärmstens das sehr gute Interview mit Amanda Askell (PhD in Philosophie und Ethik), die für die Entwicklung des Charakters von Claude verantwortlich war und dessen ethische Grundlagen maßgeblich geprägt hat: ↩
-
Tonmoy, S. et al. (2024) systematisieren die verschiedenen Techniken zur Vermeidung von Halluzinationen in LLMs und kategorisieren sie in zwei Hauptansätze: Prompt Engineering (mit Schwerpunkt auf Methoden wie Retrieval-Augmented Generation) und die Entwicklung neuer Modellarchitekturen. 2024. https://doi.org/10.48550/arXiv.2401.01313. ↩
-
Yann Lecun: Meta AI, Open Source, Limits of LLMs, AGI & the Future of AI. Lex Fridman Podcast. https://youtu.be/5t1vTLU7s40?si=X75VeC3vbgPfoMaF ↩
-
Abstraction and Reasoning Corpus. https://arcprize.org/arc ↩
-
Spannende Arbeit dazu von Laura Ruis (https://lauraruis.github.io): How Do AI Models Actually Think?. https://youtu.be/14DXtvRJeNU. Und Ruis, Laura et. al. 2024. „Procedural Knowledge in Pretraining Drives Reasoning in Large Language Models“. arXiv. https://doi.org/10.48550/arXiv.2411.12580. ↩
-
Kahneman, Daniel. 2011. Thinking, fast and slow. Thinking, fast and slow.
Andrej Karpathy bringt es als Beispiel in seiner Einführung in LLMs: [1hr Talk] Intro to Large Language Models. https://youtu.be/zjkBMFhNj_g?si=rssWKGWqW-sH5nVt ↩ -
Chollet, François. 2019. „On the Measure of Intelligence“. arXiv. https://doi.org/10.48550/arXiv.1911.01547. ↩
-
Lightman, Hunter, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, und Karl Cobbe. 2023. „Let’s Verify Step by Step“. arXiv. https://doi.org/10.48550/arXiv.2305.20050. ↩
-
Why next-token prediction is enough for AGI - Ilya Sutskever (OpenAI Chief Scientist). https://youtu.be/YEUclZdj_Sc?si=Y940MRMLiDymR2tI ↩
-
Ich empfinde Matthew Berman als jemanden, der das Thema viel zu stark hyped und nicht immer sehr seriös ist, aber seine Aussagen geben doch einen guten Überblick. The Industry Reacts to DeepSeek R1 - “Beginning of a New Era”. https://youtu.be/G1GuDyy9bTo?si=VVhtRin-GiIhhoWu ↩
-
Anthropic-CEO Dario Amodei hat es in einem aktuellen Interview noch einmal explizit gemacht: Die USA “müssen” im Bereich KI vor China liegen. Aus meiner Sicht ist Dario Amodei der seriöseste CEO der Tech-Unternehmen (er war der einzige, der nicht bei Trump aufmarschiert ist oder etwas gespendet hat; Anthropic scheint noch Anstand zu haben). ↩
-
AI Explained. o3 - wow. https://www.youtube.com/watch?v=YAgIh4aFawU\&t=1s ↩