
![]()
In einem früheren Blogbeitrag habe ich das Konzept des Vibe Coding1 vorgestellt – einen KI-gestützten Programmieransatz, bei dem Anforderungen an Software mittels Prompt Engineering aus einem Large Language Model (LLM) implementiert werden. Dies ermöglicht zwar eine schnelle Entwicklung funktionierender Software, auch ohne tiefgehende Programmiererfahrung, führt aber zu Schwierigkeiten: Der generierte Code ist häufig schwer nachvollziehbar, lässt sich nur eingeschränkt debuggen und stößt bei komplexeren Anforderungen schnell an Grenzen.
Als systematische Anwendung habe ich eine Methode entwickelt, die ich Promptotyping (Prompt + Prototyp) nennen. Promptotyping ist eine Prompt Engineering Methode, bei der Anforderungen iterativ mit gezielten Prompting-Strategien entwickelt und in klar strukturierten Dokumenten (Promptotyping Documents im Markdown-Format2) kontinuierlich verbessert werden. Ziel ist es nicht, direkt fertige Software zu erstellen, sondern Anforderungen möglichst schnell und präzise zu dokumentieren, um sie anschließend mithilfe eines LLM in Code umzusetzen. Diese Dokumente enthalten umfassenden Kontext, darunter beispielsweise den fachlichen Hintergrund der Domäne, Informationen zu verwendeten Daten sowie technische Formalisierungen. Promptotyping ist somit eng verwandt mit Vibe Coding, stellt aber gleichzeitig eine methodisch klarere und besser strukturierte Alternative dar – eine Idee, über die ich im Rahmen meiner Dissertation nachgedacht habe, bevor Vibe Coding „populär“ wurde.
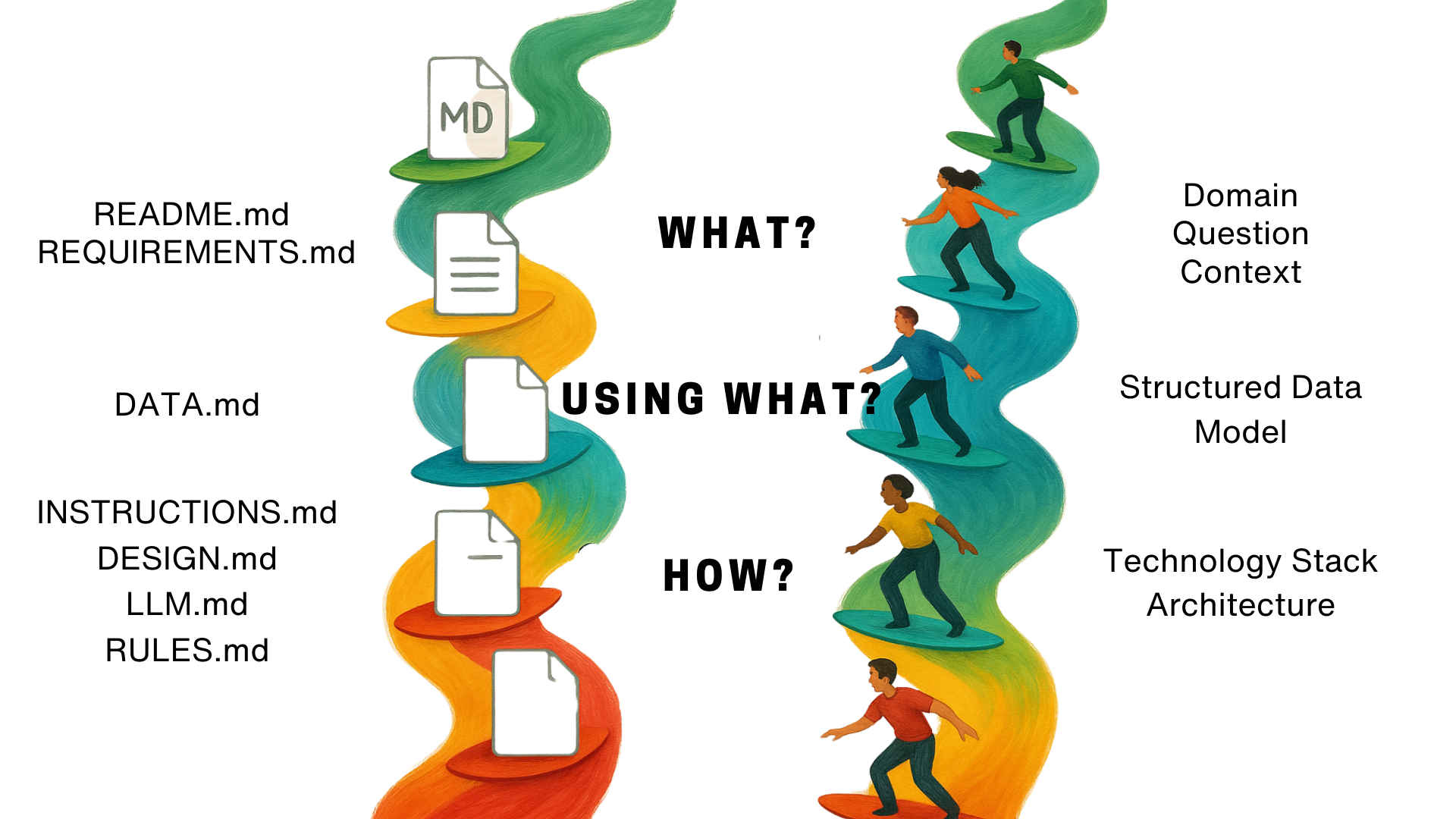
Die sogenannten Promptotyping Documents sind in drei zentrale Kategorien gegliedert. Die Kategorie “WHAT?” umfasst die Dateien README.md und REQUIREMENTS.md, die sowohl die fachliche Zielsetzung als auch Anforderungen und Kontext explizit festhalten. Die Kategorie “USING WHAT?” enthält beispielsweise DATA.md, in der die verwendeten Datenmodelle und -strukturen dokumentiert sind. Unter “HOW?” werden schließlich die Dateien INSTRUCTIONS.md, DESIGN.md, LLM.md und RULES.md zusammengefasst.3 Diese Dateien geben präzise Umsetzungsschritte, Designentscheidungen, technische Architektur und allgemeine Entwicklungsprinzipien vor.
Ziel dieser Struktur ist es, genau den richtigen Kontext bereitzustellen, damit ein LLM das gestellte Problem zumindest teilweise lösen oder hilfreiche Teilergebnisse generieren kann. Durch diese strukturierte Aufbereitung können komplexe fachliche und technische Informationen stark komprimiert und effizienter an ein LLM übertragen werden – ein Prinzip, das ich Context Compression4 nenne. Dieser Kompressionsprozess wirkt gleichzeitig als selektive Verstärkung (Context Amplification5), da relevante Inhalte betont und weniger relevante Aspekte reduziert werden. Wie bei jedem Kompressionsprozess entsteht hierbei jedoch zwangsläufig ein gewisser Informationsverlust. Vereinfacht ausgedrückt könnte man sich vorstellen, dass bei einer größeren Anzahl von Tokens die Aufmerksamkeit (Attention) des LLM auf zu viele Informationen verteilt wird, was die Verarbeitung relevanter Zusammenhänge erschweren könnte. Weniger Tokens – sofern diese präzise gewählt sind – ermöglichen dagegen eine fokussierte Verarbeitung, wodurch solidere Ergebnisse erzielt werden können.
Die hier vorgeschlagenen Dokumente dienen primär als Orientierungshilfe und sollen flexibel an Projektanforderungen angepasst werden. Keines der Dokumente ist zwingend vorgeschrieben. Allerdings haben sich einige Dokumente – insbesondere REQUIREMENTS.md und README.md – in der Praxis als hilfreich erwiesen, sodass ihre Verwendung dringend empfohlen wird. Andere Dokumente wie DATA.md oder DESIGN.md hängen stärker vom spezifischen Einsatzkontext ab: Beispielsweise ist DATA.md besonders relevant, wenn komplexe Datenstrukturen eine zentrale Rolle spielen, jedoch bei einfacheren Aufgaben oft überflüssig. Auch die Trennung zwischen INSTRUCTIONS.md und RULES.md sollte bewusst getroffen werden. Häufig empfiehlt es sich, diese beiden Dokumente zusammenzufassen, sofern es keine klaren Gründe für eine separate Nutzung gibt.
| Dokument | Frage | Funktion / Zweck | Verpflichtend? |
|---|---|---|---|
| REQUIREMENTS.md | WHAT? | Definiert das WAS – alle funktionalen (F) und nicht-funktionalen (P) Anforderungen. | Empfohlen, häufig unverzichtbar |
| README.md | WHAT? | Beschreibt das WARUM – Projektkontext, Forschungsfragen, Motivation und Domänenbeschreibung. | Empfohlen, oft wichtig |
| INSTRUCTIONS.md | HOW? | Legt das WIE UMSETZEN fest – konkrete Implementierungsschritte und aufgabenspezifische Anweisungen. | Empfohlen, projektabhängig |
| DESIGN.md | HOW? | Konkretisiert das WIE ES AUSSEHEN SOLL“ – Gestaltung, Layout und Interaktionsdesign, spezifisch auf UI und visuelle Anforderungen bezogen. | Optional, kontextabhängig |
| DATA.md | USING WHAT? | Dokumentiert das „WOMIT“ – konkrete Beispieldaten, Inhalte, Datenstrukturen, Modelle und Konfigurationsbeispiele. | Optional, je nach Datennutzung |
| RULES.md | HOW? | Definiert das NACH WELCHEN REGELN“ – globale Entwicklungsprinzipien und spezifische Regeln für den Einsatz des LLM. | Optional |
| LLM.md (z.B. GPT.md oder CLAUDE.md) | HOW? | Arbeitsgedächtnis des LLM, iterative Dokumentation der Codebasis und Prozesse. | Empfohlen, stark projektabhängig |
Das Erzeugen der Promptotyping Documents6 ist Teil der Methode und erfolgt selbst LLM-gestützt. Promptotyping verlangt eine exakte, präzise und kompakte Formulierung von Anforderungen, wodurch Mehrdeutigkeiten und Inkonsistenzen bei der Kommunikation mit LLMs reduziert werden. Die Methode zwingt uns, Probleme exakt durchzudenken – also auf den Punkt oder treffender gesagt: auf das einzelne Token genau zu formulieren. Dadurch verändert sich die Rolle von Entwickler:innen weg vom klassischen Schreiben von Programmcode hin zu methodisch-inhaltlichem Denken und beispielsweise präzisem Requirements Engineering7. Promptotyping kombiniert dafür Prinzipien aus dem Requirements Engineering, um Anforderungen systematisch zu erfassen und zu validieren, dem User-Centred Design8, um Nutzerbedürfnisse empirisch und iterativ umzusetzen, sowie einer speziell darauf aufbauenden Herangehensweise, dem Scholar-Centred Design9, das die fachlich-epistemologischen Anforderungen der Forschenden berücksichtigt, indem Forschungsfragen und technische Anforderungen parallel entstehen und iterativ aufeinander abgestimmt werden. Diese Idee wird derzeit bei uns (DHCraft) gemeinsam mit Kooperationspartnern anhand konkreter Prototypen digitaler Forschungswerkzeuge erprobt. Solche Ansätze stärken einerseits die Autonomie von Forschenden und reduzieren klassische Abhängigkeiten (Uni-IT, Rechenzentren, etc.), erzeugen andererseits jedoch neue Abhängigkeiten von LLM-Anbietern, die perspektivisch durch zunehmend effizientere, lokal betreibbare Modelle wieder abgeschwächt werden könnten. Es gibt hierbei kein einfaches Schwarz und Weiß, sondern viele differenzierte Grautöne.
Der Promptotyping-Prozess erfolgt konkret in vier iterativen und aufeinander aufbauenden Phasen, die am User-Centred Design orientiert sind. Dadurch wird sichergestellt, dass Nutzer:innenanforderungen systematisch erfasst, konsequent umgesetzt und kontinuierlich validiert werden. Durch die enge Einbindung von Domänenexpert:innen (experts-in-the-loop10) in der Evaluationsphase wird gewährleistet, dass die entwickelten Prototypen nicht nur technisch robust, sondern auch methodisch fundiert und präzise auf die epistemologischen Bedürfnisse (z. B. Forschungsfragen, Erkenntnisinteressen) der Forschenden abgestimmt sind. Die Domänenexpert:innen prüfen in jeder Iteration sowohl die Prototypen als auch die kontinuierlich aktualisierten und versionierten Promptotyping-Dokumente kritisch. Diese iterative Auseinandersetzung mit den vom und aus dem LLM extrapolierten Möglichkeitsräumen fördert eine vertiefte Beschäftigung mit dem Forschungsgegenstand. Dies ist aktuell jedoch eine These, deren empirische Validierung noch aussteht. Zur Illustration möchte ich dies in einem ersten einfachen Experiment veranschaulichen:
Ein Beispiel: “Subject-Verb Inversion in Academic Writing: Interactive analysis of inversion patterns in academic English”
Der Subject-Verb Inversion Finder11 entstand ursprünglich als exploratives Vibe-Coding-Experiment, das ich für einen Vortrag erarbeitet habe.12 Obwohl ich selbst kein Domänenexperte bin, erlaubten mir meine bisherigen Erfahrungen aus den Digital Humanities zumindest grundlegende Fragestellungen und mögliche Anforderungen abzuschätzen. Mithilfe von Claude 3.7 Sonnet entstand relativ rasch, also an einem Nachmittag, ein erster Prototyp, dessen einziger Input die Korpusdaten (als Snippets) und eine PowerPoint-Folie war, auf der mögliche Forschungsfragen anhand einiger Beispiele umrissen wurden (WHAT). Dabei zeigte sich allerdings schnell, dass eine exakte methodische Umsetzung schwierig wird, wenn domänenspezifisches Fachwissen fehlt – wie ich ohnehin erwartet hatte.
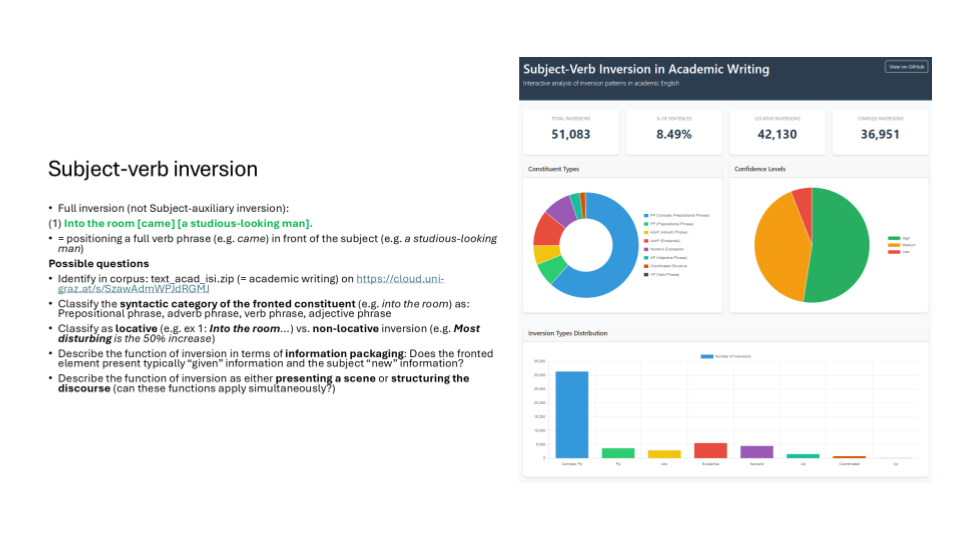
Im Experiment wurden zwei unterschiedliche Lösungswege ausprobiert: Der erste von Claude vorgeschlagene Ansatz war die Identifikation der Inversionen mithilfe regulärer Ausdrücke (RegEx). Hierbei merkte Claude jedoch stets an, dass dies keine vollständige Lösung darstellen könnte. Der zweite Ansatz wurde von mir initiiert und bestand darin, das Problem mithilfe der NLP-Bibliothek spaCy13 anzugehen, die mir bekannt war, mit der ich aber zuvor noch nicht gearbeitet hatte. Ziel war jeweils, aus einem Plain-Text-Korpus automatisch Subject-Verb-Inversionen zu extrahieren.
Dieses Experiment zeigte, dass durchaus ein interessanter methodischer und analytischer Möglichkeitsraum vorhanden ist, gleichzeitig wurde aber deutlich, dass ohne ausreichendes domänenspezifisches Wissen eine methodisch exakte Umsetzung nicht möglich ist. Das erzielte Resultat ist dennoch solide und vorzeigbar, insbesondere wenn man bedenkt, dass es sich hierbei lediglich um ein relativ exploratives Experiment von etwa einem halben Arbeitstag handelt. Mit mehr Zeit hätten sicherlich noch deutlich bessere Ergebnisse erzielt werden können.
Um das Tool methodisch präzise und wissenschaftlich belastbar weiterzuentwickeln, ist daher die Einbindung linguistischer Expertise unerlässlich. Genau deswegen bietet sich Promptotyping als scholar-centred Requirements-Engineering-Methode an, da diese Methode auf kontinuierliches menschliches Feedback angewiesen ist. Erste beispielhafte Promptotyping-Dokumente in einer noch vorläufigen Form sind bereits vorhanden: eine CLAUDE.md, welche die technische Logik und den Code dokumentiert, sowie eine ReadMe.md, welche den fachlichen Projektkontext und die Domäne kurz beschreibt.
In zukünftigen Beiträgen werden wir konkrete Workflows Schritt für Schritt dokumentieren sowie methodische Ansätze zur systematischen Evaluation und zum Benchmarking von Promptotyping diskutieren. Eine seriöse Evaluation ist eine harte Nuss, die es zu knacken gilt. Daraus könnten sich neue Impulse für generelle Prompting-Techniken ergeben, die sich auch auf andere Bereiche wie Modellierung oder Forschungsprozesse übertragen lassen – insbesondere da LLM im Jahr 2025 bereits erhebliche Fortschritte gemacht haben und weitere folgen werden.
-
Siehe dazu meinen Beitrag: “Haters gonna hate”: Warum die Kritik an Vibe Coding berechtigt ist – und welche Proto-AGI-Potenziale sie übersieht. https://dhcraft.org/excellence/blog/Vibe-Coding ↩
-
Strukturierte Prompts sind tendenziell besser. Strukturierte Promptformate (Markdown, JSON, YAML) erzielen tendenziell bessere Ergebnisse gegenüber einfachem Plain-Text-Format. Jedoch gibt es keine universell optimale Struktur; die Wahl des besten Formats ist stets abhängig vom spezifischen Anwendungskontext und Modell. He, Jia, Mukund Rungta, David Koleczek, Arshdeep Sekhon, Franklin X. Wang, and Sadid Hasan. ‘Does Prompt Formatting Have Any Impact on LLM Performance?’ arXiv, 15 November 2024. https://doi.org/10.48550/arXiv.2411.10541 ↩
-
In Anlehnung an das Reference Model of Information Visualisation von Card et al. (1999) oder Munzner’s “What?, Why?, How?”. Munzner, T. 2014. Visualization Analysis and Design. 1. Edition. New York: CRC PressA K Peters/CRC Press. https://doi.org/10.1201/b17511. Card, Stuart K., Jock D. Mackinlay, and Ben Shneiderman. 1999. Readings in Information Visualization: Using Vision to Think. The Morgan Kaufmann Series in Interactive Technologies. San Francisco, Calif: Morgan Kaufmann Publishers ↩
-
Context Compression finde ich persönlich besser als Prompt Compression, weil es viel mehr darum geht, den Inhalt auf den Punkt zu bringen. Li et al. (2024) unterscheidet verschiedene Methoden zur Prompt-Kompression für große Sprachmodelle. Auch Chang et al. (2024) beschreiben Ansätze zur effizienten Prompt-Komprimierung. Beide Arbeiten analysieren Methoden zur Reduzierung der Inferenzzeit und des Speicherbedarfs bei gleichzeitiger Erhaltung der Antwortqualität. Li, Zongqian, Yinhong Liu, Yixuan Su, and Nigel Collier. ‘Prompt Compression for Large Language Models: A Survey’. arXiv, 17 October 2024 https://doi.org/10.48550/arXiv.2410.12388. Und: Chang, Kaiyan, Songcheng Xu, Chenglong Wang, Yingfeng Luo, Xiaoqian Liu, Tong Xiao, and Jingbo Zhu. ‘Efficient Prompting Methods for Large Language Models: A Survey’. arXiv, 2 December 2024. https://doi.org/10.48550/arXiv.2404.01077 ↩
-
Der Begriff ist eine Eigenkreation ↩
-
Templates und wie man sie erstellt werden in einem späteren Beitrag im Detail diskutiert werden ↩
-
Requirements Engineering ist ein systematischer und iterativer Prozess zur Identifikation, Dokumentation, Analyse, Priorisierung, Validierung und Verwaltung von Stakeholder-Anforderungen für die Entwicklung von Produkten. Broy, Manfred, und Marco Kuhrmann. 2021 „Anforderungsanalyse und Anforderungsmanagement“. In Einführung in die Softwaretechnik, herausgegeben von Manfred Broy und Marco Kuhrmann, 199–222. Xpert.press. Berlin, Heidelberg: Springer. https://doi.org/10.1007/978-3-662-50263-1_5 ↩
-
User-Centred Design ist ein iterativer Entwicklungsansatz, der auf Grundlage empirisch ermittelter Nutzungsanforderungen und Nutzungskontexte interaktive Systeme gestaltet. Der Prozess umfasst die Schritte Analyse, Design und Prototyping, sowie die Evaluierung entstandener Prototypen. Jetter, Hans-Christian. 2022. „D 3 Mensch-Computer-Interaktion, Usability und User Experience“. In Grundlagen der Informationswissenschaft, 525–34. De Gruyter Saur. https://doi.org/10.1515/9783110769043-045 ↩
-
Das ist ein Konzept, das ich im Zuge meiner Dissertation entwickelt und angewandt habe. Scholar-Centred Design ist eine iterative Entwicklungsmethodik, die wissenschaftliche Praktiken und epistemologische Anforderungen ins Zentrum technischer Implementierungen stellt. Sie berücksichtigt explizit die nicht-linearen Prozesse wissenschaftlicher Erkenntnis sowie die parallele Entwicklung von Forschungsfragen und technischen Anforderungen, um Tools, Informationssysteme und Datenmodelle zu schaffen. Pollin 2025: Modelling, Operationalising and Exploring Historical Information. Using Historical Financial Sources as an Example. ↩
-
Auch hier gibt es eine Parallele zu Munzner. Sie setzt auch den “human-in-the-loop” beim Umsetzen von Informationsvisualisierungen. https://doi.org/10.1201/b17511 ↩
-
https://dhcraft.org/excellence/promptotyping/subject-verb-inversion-finder ↩
-
Generative AI and Prompt Engineering. Analysing Subject-Verb Inversion in Academic Writing. https://docs.google.com/presentation/d/1alDx6nVV1VeUJMh8SdRBFkHqaQO6dFENy_eLS9q3XDw/edit?usp=sharing ↩
-
spaCy ist eine Python-Bibliothek für Natural Language Processing (NLP), die Textanalyse und linguistische Verarbeitung ermöglicht, einschließlich Tokenisierung, Named-Entity-Erkennung, sowie Integration von Machine-Learning-Modellen. ↩